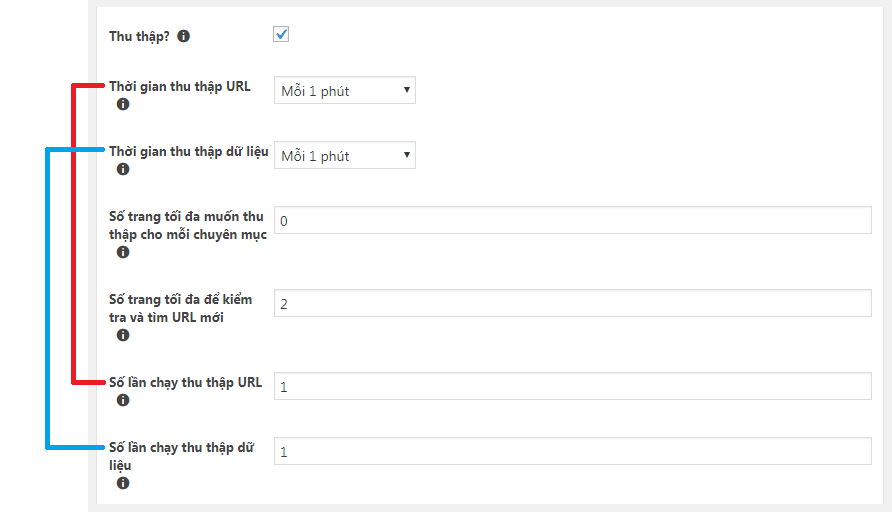
Thời gian thu thập URL
Đây là thiết lập khoảng thời gian thu thập URL. Hãy hiểu như này, nếu bạn đặt là 1 phút thì con BOT sẽ bò vào chuyên mục và cứ 1 phút nó sẽ tìm và lưu các URL bài viết mới vào CSDL.
Thời gian thu thập dữ liệu
Chính là khoảng thời gian để xử lý và lưu các bài viết. Hãy tưởng tượng, nếu đặt 1 phút thì con BOT sẽ duyệt các URL bài viết mà nó đã lưu vào CSDL trước đó và bắt đầu xử lý để đăng lên thành 1 bài viết hoàn chỉnh.
Số lần chạy thu thập URL
Trong khoảng thời gian thu thập URL mà bạn đặt ở trên thì bạn muốn có bao nhiêu tiến trình thu thập URL được chạy?
Nếu bạn đặt thời gian thu thập URL là 1 phút và số lần chạy thu thập URL là 3 thì cứ 1 phút sẽ có 3 tiến trình thu thập URL được chạy.
Vậy nếu chuyên mục được phân trang với 10 bài viết mỗi trang thì cứ 1 phút chạy 3 tiến trình thu thập => con BOT sẽ lưu về thêm 30 URL bài viết của 3 trang trong chuyên mục.
Số lần chạy thu thập dữ liệu
Tương tự, nếu bạn đặt thời gian thu thập dữ liệu là 1 phút và số lần chạy thu thập dữ liệu là 3 thì cứ 1 phút sẽ có 3 bài viết được xử lý và đăng lên.
Số trang tối đa muốn thu thập cho mỗi chuyên mục
Thu thập dữ liệu tối đa bao nhiêu trang cho mỗi chuyên mục? Đặt 0 để thu thập tất cả các trang trong chuyên mục.
Số trang tối đa để kiểm tra và tìm URL mới
Kiểm tra bao nhiêu trang trước khi quay trở lại kiểm tra trang đầu tiên của chuyên mục nếu không tìm thấy các URL mới? Mặc định: 0 sẽ kiểm tra tất cả các trang cho đến trang cuối cùng.
Ví dụ: nếu bạn điền 3 và không có URL mới nào được tìm thấy trong 3 trang khác nhau của một chuyên mục, Ví dụ: trang 1, 2, và 3, sau đó trình thu thập sẽ đi đến trang đầu tiên để tìm các URL mới, mà không phải cố gắng tìm kiếm ở trang thứ 4 và các trang sau trang thứ 4.
Cách sử dụng hiệu quả
Bây giờ đến lúc mình giải thích nhé. Bạn cần phải tưởng tượng ra cách mà tool nó sẽ làm việc. Hãy tưởng tượng như này (gọi đây là ví dụ 1).
Giả sử trong chuyên mục phân trang với 10 bài mỗi trang.
Thời gian thu thập URL và Thời gian thu thập dữ liệu đều là: 1 phút
Số lần chạy thu thập URL: 1
Số lần chạy thu thập dữ liệu: 5
Vậy thì:
Phút thứ 1: sẽ có 10 URL được lưu vào CSDL. (0/10)
Phút thứ 2: sẽ có 5 bài được đăng và thêm 10 URL vào CSDL. (5/20)
Phút thứ 3: sẽ có 5 bài được đăng và thêm 10 URL vào CSDL. (10/30)
Phút thứ 4: sẽ có 5 bài được đăng và thêm 10 URL vào CSDL. (15/40)
Cứ thế, cứ thế số URL đang chờ sẽ nhiều hơn gấp nhiều lần số bài viết được đăng. Điều này là không cần thiết vì chúng ta nên thiết lập để thêm URL tới đâu sẽ đăng bài tới đó hoặc chí ít là số bài được đăng sẽ "đuổi" kịp số URL đang chờ. Điều này cũng có nghĩa là bạn sẽ tiết kiệm được RAM và CPU vào các tiến trình thu thập URL không cần thiết.
Vậy nên trong trường hợp này hãy tăng khoảng thời gian thu thập URL lên, ví dụ 2 phút thu thập URL 1 lần, để:
Nếu như mình vẫn lấy giả sử ở trên thì (gọi đây là ví dụ 2):
Phút thứ 1: sẽ có 10 URL được lưu vào CSDL. (0/10)
Phút thứ 2: sẽ có 5 bài được đăng và không thêm URL nào vào CSDL. (5/10)
Phút thứ 3: sẽ có 5 bài được đăng và thêm 10 URL vào CSDL. (10/20)
Phút thứ 4: sẽ có 5 bài được đăng và không thêm URL nào vào CSDL. (15/20)
Bạn thấy ý nghĩa gì chứ?
Đó là:
Ở ví dụ 1:
Phút thứ 1: Tiến trình thu thập URL được chạy.
Phút thứ 2: Tiến trình thu thập URL và tiến trình thu thập dữ liệu đều được chạy.
Phút thứ 3: Tiến trình thu thập URL và tiến trình thu thập dữ liệu đều được chạy.
Phút thứ 4: Tiến trình thu thập URL và tiến trình thu thập dữ liệu đều được chạy.
Ở ví dụ 2:
Phút thứ 1: Tiến trình thu thập URL được chạy.
Phút thứ 2: Chỉ tiến trình thu thập dữ liệu được chạy.
Phút thứ 3: Tiến trình thu thập URL và tiến trình thu thập dữ liệu đều được chạy.
Phút thứ 4: Chỉ tiến trình thu thập dữ liệu được chạy.
Như vậy là bạn đã tiết kiệm được khá nhiều RAM và CPU rồi nhé, nếu như bạn chạy nhiều chiến dịch thì sẽ tiết kiệm đáng kể đó. Tránh tình trạng bị quá tải. Hãy sử dụng hợp lý nhé.
Bạn cũng phải cân nhắc thời gian xử lý 1 bài viết để đặt thời gian thu thập và số lần thu thập theo thời gian đó một cách hợp lý nhất.
Giả sử bạn đặt 1 phút đăng 5 bài, nhưng 5 bài đó quá nặng do chứa nhiều hình ảnh hoặc do server của mục tiêu load chậm, v.v… dẫn tới trong 1 phút con BOT không thể xử lý được hết 5 bài (5 tiến trình) và sang phút thứ 2 sẽ lại thêm 5 tiến trình nữa được chạy. Vậy là sẽ chồng chéo tiến trình lên nhau dẫn tới nghẽn tiến trình và tool sẽ không chạy nữa.
Trong trường hợp như vậy, hãy sử dụng tính năng Mở khóa URL trong Công cụ để mở khóa các URL đang bị treo.
Tuy nhiên hãy thật khôn ngoan trong việc thiết lập các thông số để hạn chế tối đa việc nghẽn và lỗi thu thập.
Để hỗ trợ tính toán khoảng thời gian và đưa ra được các thông số cấu hình hợp lý thì bạn hãy sử dụng Thử nghiệm, tại trang Thử nghiệm bạn sẽ thấy Bộ nhớ sử dụng và thời gian cần để xử lý 1 tiến trình. Chúc bạn thành công! 😉